k-anonymity
Today's blog post is about an important concept regarding database anonymization called k-anonymity.
Before I can explain what k-anonymity means, I need to explain what quasi identifiers are.
A person has several personally identifiable information about themselves, such as age, address, and IP.
Quasi identifiers
Next to those identifiers, we also possess quasi identifiers like ZIP code, sex, and age. Those informations themselves can not identify us directly, but indirectly. An attacker can, for example, use auxiliary information from various sources and link them via the ZIP code. Also, using just the three quasi identifiers shown in this video, ZIP, sex, and age, is enough to identify 87% of the US population.
Medical database
Knowing that, let's look at an example database which might exist in some hospital somewhere. We have the name of the patient, their age, sex, ZIP code and finally the disease they're in for.
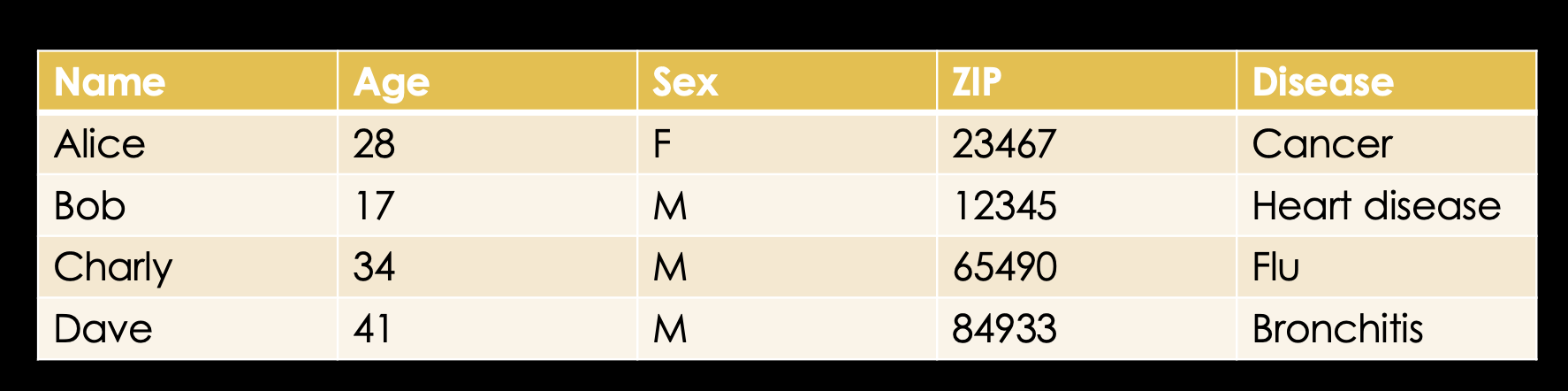
Before releasing any data, of course first the name - the identifier - has to be deleted.
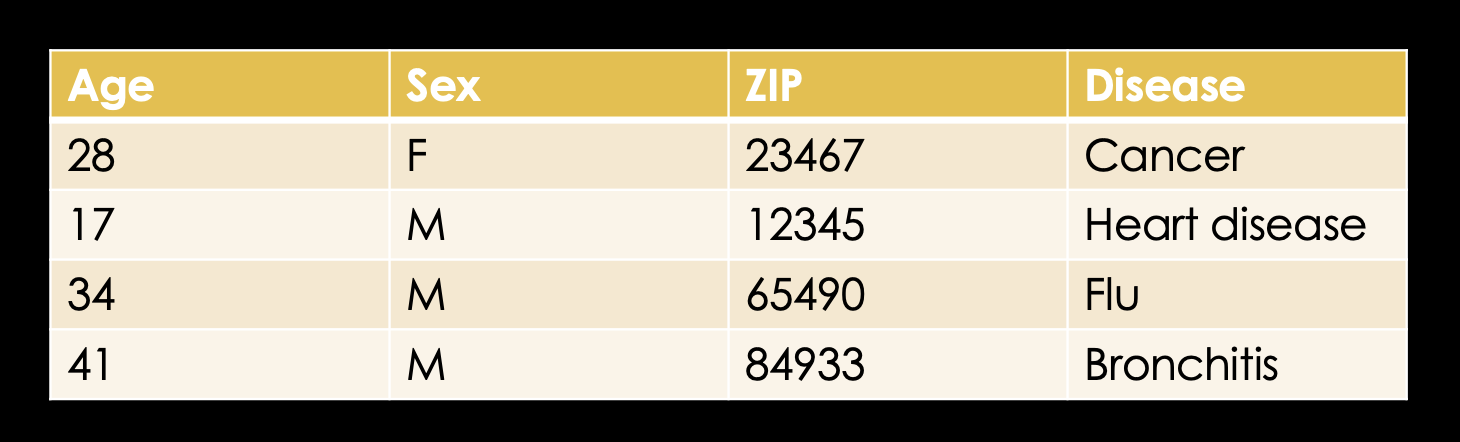
But knowing what we know that, that age, sex, and ZIP code are enough to identify you to a pretty high degree, should we delete those as well? Is the database still in any way usable if we do that?
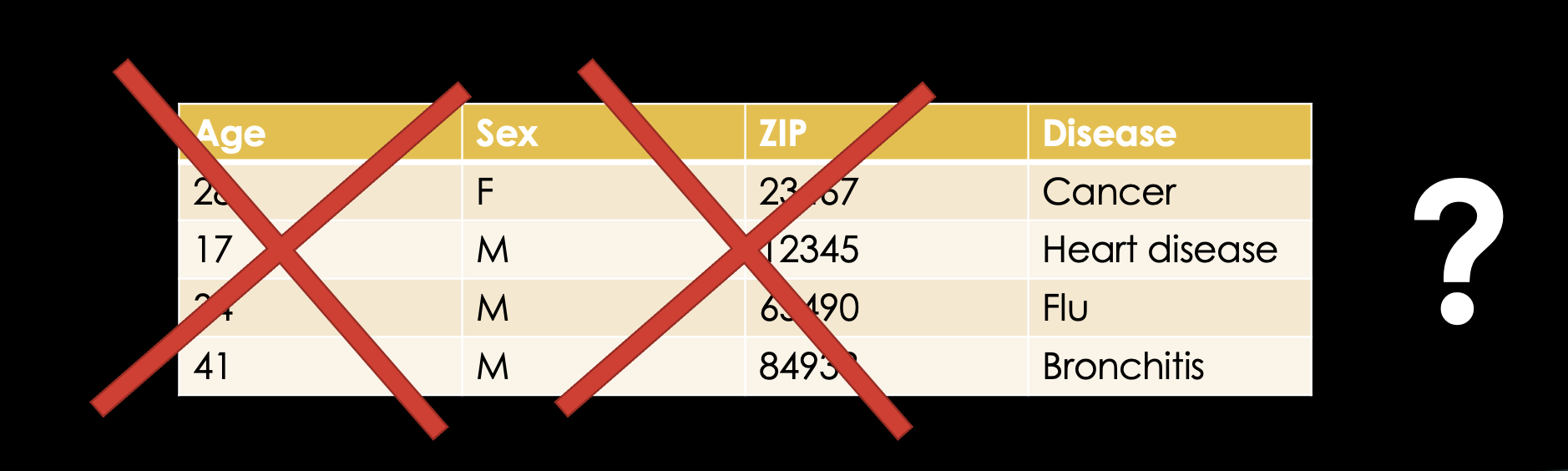
Generalization
Let's not jump the gun right away. First, we can try to apply a concept called "generalization". You can generalize certain data in order to minimize disclosure risks. For example, we could generalize the age in 10 year intervals.
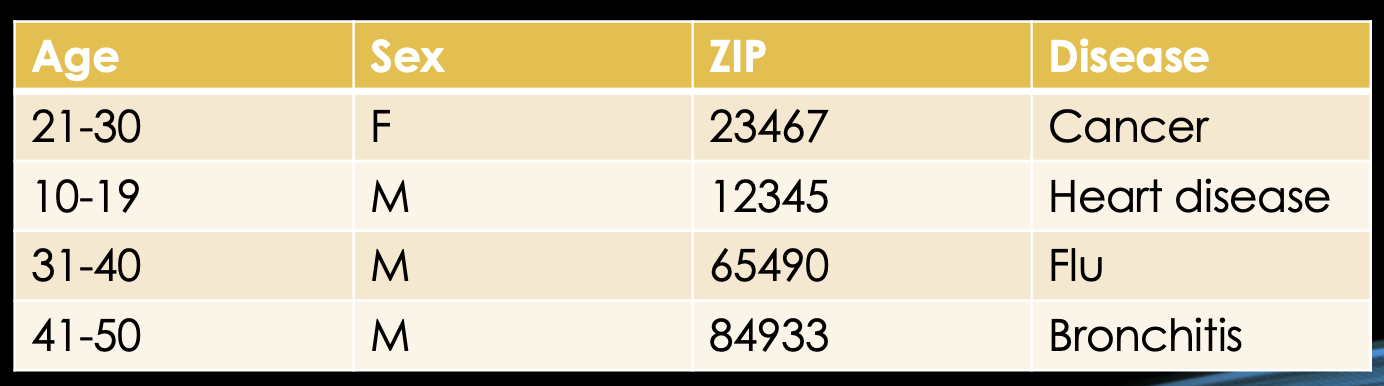
However, as you can see, the four individuals in the database are still uniquely identifiable, so obviously we lost some information, but the privacy is gain is very little. How do we know if the disclosure risk is now less than it was before?
k-anonymity
Here, k-anonymity comes into play. k-anonymity means, that an individual's quasi identifiers have to be equivalent to at least k-1 other individuals. Those k individuals now form an equivalence class. So, for example, if we generalize the age to intervals of 20, we can see that the first two cells are equal and the second two cells are equal.
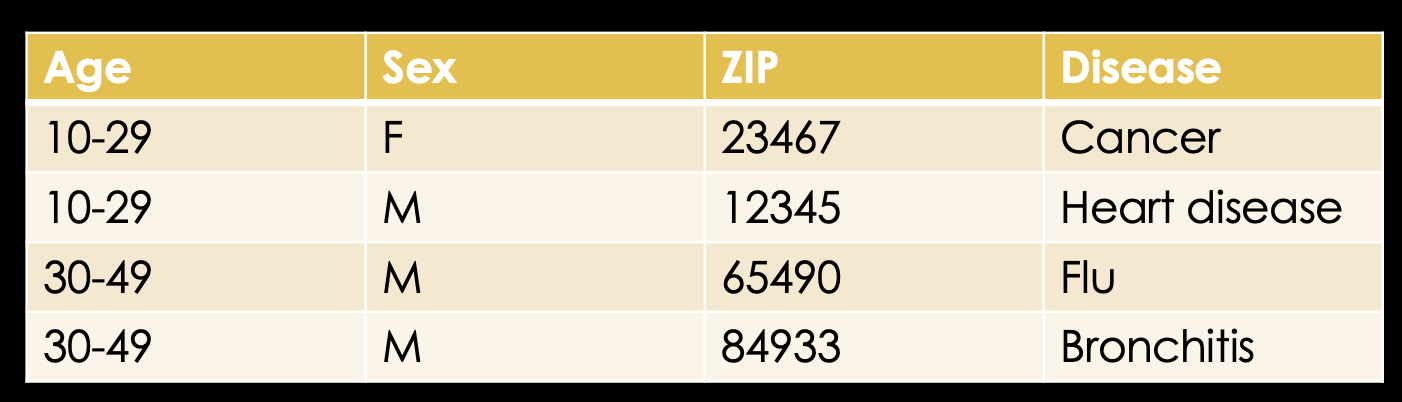
Meaning we achieved a k equals 2 anonymity. But are these really equivalence classes? What about the sex? We can see that the first two rows differ in their sex. Also the ZIP codes are still unique for all individuals.

Suppression
Here, we can use another concept called suppression. We can suppress information and thereby form equivalence classes. We don't need to suppress the sex of the bottom two rows as those are already equal.
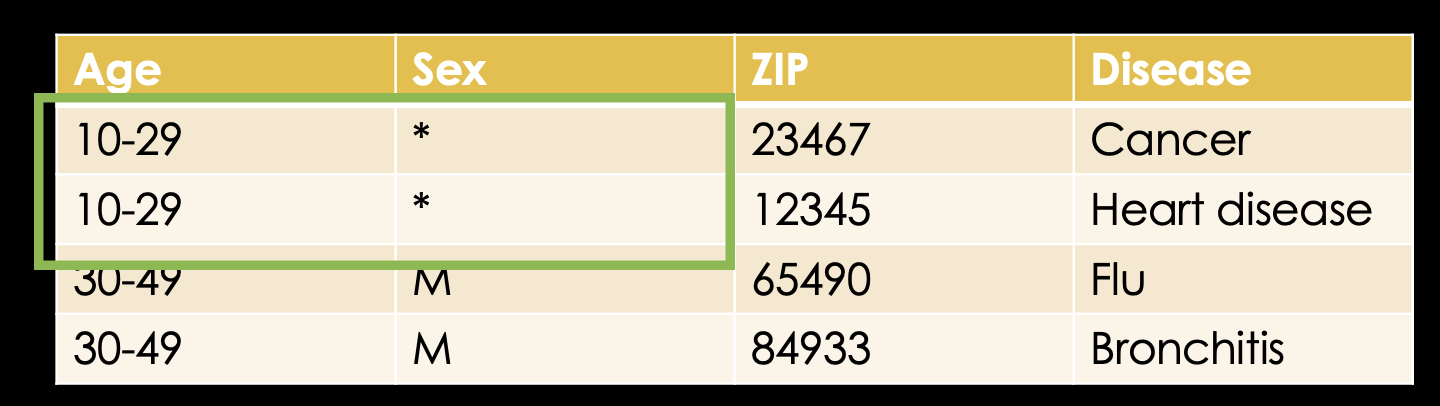
Next, we need to suppress the ZIP code information and now we have an actual 2-anonymous table.
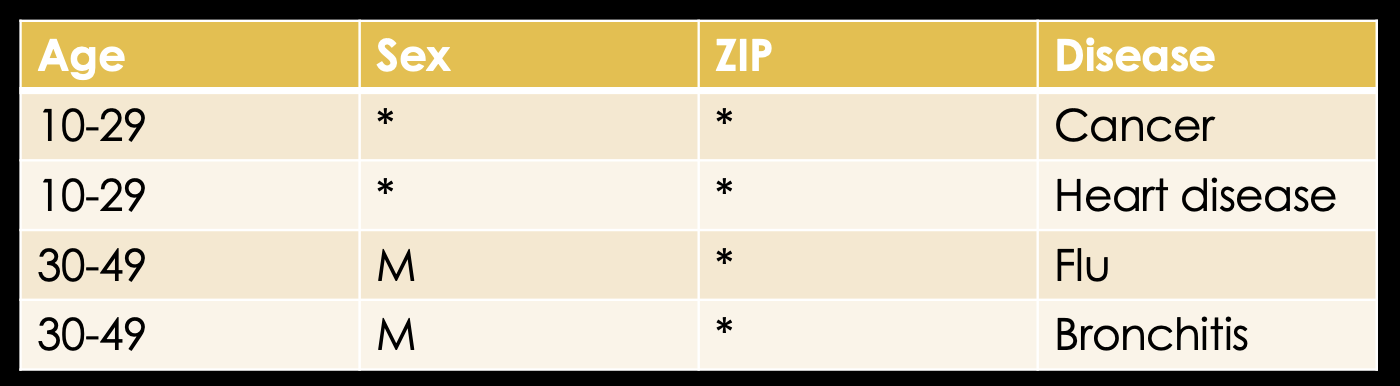
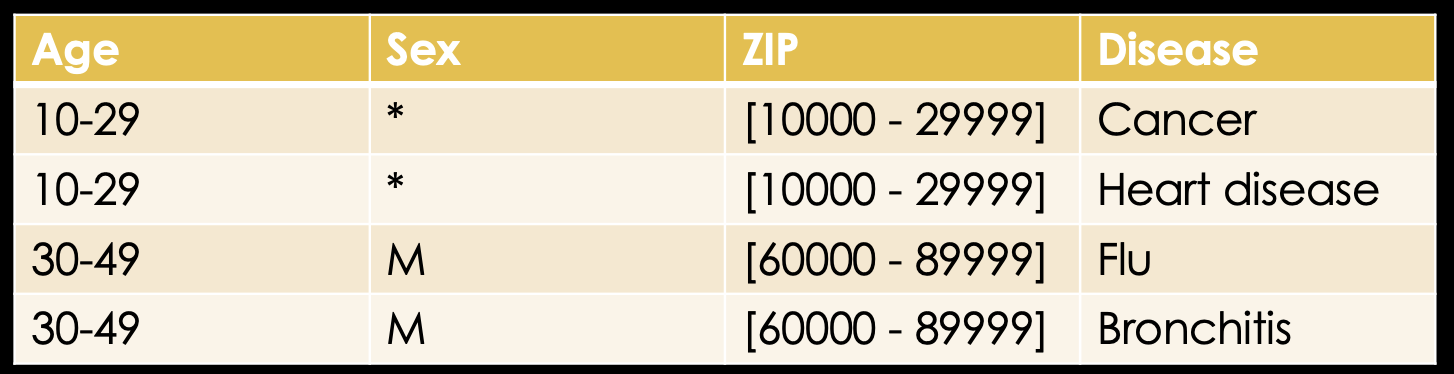
Note, that we could've just as easily generalized the ZIP code and, thus, retained some information that is lost by suppression.
Conclusion
In general, when dealing with anonymization, and k-anonymity in particular, we always have to weigh the utility of the data against the disclosure risk. k-anonymity is not the be all end all of database anonymization but is an important concept to understand before dealing with more sophisticated concepts, such as differential privacy.
-PK, 03.02.2023